typedef struct _tzm_secure_config
{
uint32_t cm33_vtor_addr; /*! CM33 Secure vector table address */
uint32_t cm33_vtor_ns_addr; /*! CM33 Non-secure vector table address */
uint32_t cm33_nvic_itns0; /*! CM33 Interrupt target non-secure register 0 */
uint32_t cm33_nvic_itns1; /*! CM33 Interrupt target non-secure register 1 */
uint32_t mcm33_vtor_addr; /*! MCM33 Secure vector table address */
uint32_t cm33_mpu_ctrl; /*! MPU Control Register.*/
uint32_t cm33_mpu_mair0; /*! MPU Memory Attribute Indirection Register 0 */
uint32_t cm33_mpu_mair1; /*! MPU Memory Attribute Indirection Register 1 */
uint32_t cm33_mpu_rbar0; /*! MPU Region 0 Base Address Register */
uint32_t cm33_mpu_rlar0; /*! MPU Region 0 Limit Address Register */
uint32_t cm33_mpu_rbar1; /*! MPU Region 1 Base Address Register */
uint32_t cm33_mpu_rlar1; /*! MPU Region 1 Limit Address Register */
uint32_t cm33_mpu_rbar2; /*! MPU Region 2 Base Address Register */
uint32_t cm33_mpu_rlar2; /*! MPU Region 2 Limit Address Register */
uint32_t cm33_mpu_rbar3; /*! MPU Region 3 Base Address Register */
uint32_t cm33_mpu_rlar3; /*! MPU Region 3 Limit Address Register */
uint32_t cm33_mpu_rbar4; /*! MPU Region 4 Base Address Register */
uint32_t cm33_mpu_rlar4; /*! MPU Region 4 Limit Address Register */
uint32_t cm33_mpu_rbar5; /*! MPU Region 5 Base Address Register */
uint32_t cm33_mpu_rlar5; /*! MPU Region 5 Limit Address Register */
uint32_t cm33_mpu_rbar6; /*! MPU Region 6 Base Address Register */
uint32_t cm33_mpu_rlar6; /*! MPU Region 6 Limit Address Register */
uint32_t cm33_mpu_rbar7; /*! MPU Region 7 Base Address Register */
uint32_t cm33_mpu_rlar7; /*! MPU Region 7 Limit Address Register */
uint32_t cm33_mpu_ctrl_ns; /*! Non-secure MPU Control Register.*/
uint32_t cm33_mpu_mair0_ns; /*! Non-secure MPU Memory Attribute Register 0 */
uint32_t cm33_mpu_mair1_ns; /*! Non-secure MPU Memory Attribute Register 1 */
uint32_t cm33_mpu_rbar0_ns; /*! Non-secure MPU Region 0 Base Address Register */
uint32_t cm33_mpu_rlar0_ns; /*! Non-secure MPU Region 0 Limit Address Register */
uint32_t cm33_mpu_rbar1_ns; /*! Non-secure MPU Region 1 Base Address Register */
uint32_t cm33_mpu_rlar1_ns; /*! Non-secure MPU Region 1 Limit Address Register */
uint32_t cm33_mpu_rbar2_ns; /*! Non-secure MPU Region 2 Base Address Register */
uint32_t cm33_mpu_rlar2_ns; /*! Non-secure MPU Region 2 Limit Address Register */
uint32_t cm33_mpu_rbar3_ns; /*! Non-secure MPU Region 3 Base Address Register */
uint32_t cm33_mpu_rlar3_ns; /*! Non-secure MPU Region 3 Limit Address Register */
uint32_t cm33_mpu_rbar4_ns; /*! Non-secure MPU Region 4 Base Address Register */
uint32_t cm33_mpu_rlar4_ns; /*! Non-secure MPU Region 4 Limit Address Register */
uint32_t cm33_mpu_rbar5_ns; /*! Non-secure MPU Region 5 Base Address Register */
uint32_t cm33_mpu_rlar5_ns; /*! Non-secure MPU Region 5 Limit Address Register */
uint32_t cm33_mpu_rbar6_ns; /*! Non-secure MPU Region 6 Base Address Register */
uint32_t cm33_mpu_rlar6_ns; /*! Non-secure MPU Region 6 Limit Address Register */
uint32_t cm33_mpu_rbar7_ns; /*! Non-secure MPU Region 7 Base Address Register */
uint32_t cm33_mpu_rlar7_ns; /*! Non-secure MPU Region 7 Limit Address Register */
uint32_t cm33_sau_ctrl;
uint32_t cm33_sau_rbar0;/*! SAU Region 0 Base Address Register */
uint32_t cm33_sau_rlar0;/*! SAU Region 0 Limit Address Register */
uint32_t cm33_sau_rbar1;/*! SAU Region 1 Base Address Register */
uint32_t cm33_sau_rlar1;/*! SAU Region 1 Limit Address Register */
uint32_t cm33_sau_rbar2;/*! SAU Region 2 Base Address Register */
uint32_t cm33_sau_rlar2;/*! SAU Region 2 Limit Address Register */
uint32_t cm33_sau_rbar3;/*! SAU Region 3 Base Address Register */
uint32_t cm33_sau_rlar3;/*! SAU Region 3 Limit Address Register */
uint32_t cm33_sau_rbar4;/*! SAU Region 4 Base Address Register */
uint32_t cm33_sau_rlar4;/*! SAU Region 4 Limit Address Register */
uint32_t cm33_sau_rbar5;/*! SAU Region 5 Base Address Register */
uint32_t cm33_sau_rlar5;/*! SAU Region 5 Limit Address Register */
uint32_t cm33_sau_rbar6;/*! SAU Region 6 Base Address Register */
uint32_t cm33_sau_rlar6;/*! SAU Region 6 Limit Address Register */
uint32_t cm33_sau_rbar7;/*! SAU Region 7 Base Address Register */
uint32_t cm33_sau_rlar7;/*! SAU Region 7 Limit Address Register */
uint32_t flash_rom_slave_rule;/*! FLASH/ROM Slave Rule Register 0 */
uint32_t flash_mem_rule0;/*! FLASH Memory Rule Register 0 */
uint32_t flash_mem_rule1;/*! FLASH Memory Rule Register 1 */
uint32_t flash_mem_rule2;/*! FLASH Memory Rule Register 2 */
uint32_t rom_mem_rule0;/*! ROM Memory Rule Register 0 */
uint32_t rom_mem_rule1;/*! ROM Memory Rule Register 1 */
uint32_t rom_mem_rule2;/*! ROM Memory Rule Register 2 */
uint32_t rom_mem_rule3;/*! ROM Memory Rule Register 3 */
uint32_t ramx_slave_rule;
uint32_t ramx_mem_rule0;
uint32_t ram0_slave_rule;
uint32_t ram0_mem_rule0;/*! RAM0 Memory Rule Register 0 */
uint32_t ram0_mem_rule1;/*! RAM0 Memory Rule Register 1 */
uint32_t ram1_slave_rule; /*! RAM1 Memory Rule Register 0 */
uint32_t ram1_mem_rule1;/*! RAM1 Memory Rule Register 1 */
uint32_t ram2_mem_rule1;/*! RAM2 Memory Rule Register 1 */
uint32_t ram3_mem_rule0;/*! RAM3 Memory Rule Register 0 */
uint32_t ram3_mem_rule1;/*! RAM3 Memory Rule Register 1 */
uint32_t ram4_slave_rule;
uint32_t ram2_mem_rule0;
uint32_t ram3_slave_rule;
uint32_t ram1_mem_rule0;
uint32_t ram2_slave_rule;
uint32_t ram4_mem_rule0;/*! RAM4 Memory Rule Register 0 */
uint32_t apb_grp_slave_rule;/*! APB Bridge Group Slave Rule Register */
uint32_t apb_grp0_mem_rule0;/*! APB Bridge Group 0 Memory Rule Register 0 */
uint32_t apb_grp0_mem_rule1;/*! APB Bridge Group 0 Memory Rule Register 1 */
uint32_t apb_grp0_mem_rule2;/*! APB Bridge Group 0 Memory Rule Register 2 */
uint32_t apb_grp0_mem_rule3;/*! APB Bridge Group 0 Memory Rule Register 3 */
uint32_t apb_grp1_mem_rule0;/*! APB Bridge Group 1 Memory Rule Register 0 */
uint32_t apb_grp1_mem_rule1;/*! APB Bridge Group 1 Memory Rule Register 1 */
uint32_t apb_grp1_mem_rule2;/*! APB Bridge Group 1 Memory Rule Register 2 */
uint32_t apb_grp1_mem_rule3;/*! APB Bridge Group 1 Memory Rule Register 3 */
uint32_t ahb_periph0_slave_rule0;/*! AHB Peripherals 0 Slave Rule Register 0 */
uint32_t ahb_periph0_slave_rule1;/*! AHB Peripherals 0 Slave Rule Register 1 */
uint32_t ahb_periph1_slave_rule0;/*! AHB Peripherals 1 Slave Rule Register 0 */
uint32_t ahb_periph1_slave_rule1;/*! AHB Peripherals 1 Slave Rule Register 1 */
uint32_t ahb_periph2_slave_rule0;/*! AHB Peripherals 2 Slave Rule Register 0 */
uint32_t ahb_periph2_slave_rule1;/*! AHB Peripherals 2 Slave Rule Register 1 */
uint32_t ahb_periph2_mem_rule0;/*! AHB Peripherals 2 Memory Rule Register 0*/
uint32_t usb_hs_slave_rule0; /*! HS USB Slave Rule Register 0 */
uint32_t usb_hs__mem_rule0; /*! HS USB Memory Rule Register 0 */
uint32_t sec_gp_reg0;/*! Secure GPIO Register 0 */
uint32_t sec_gp_reg1;/*! Secure GPIO Register 1 */
uint32_t sec_gp_reg2;/*! Secure GPIO Register 2 */
uint32_t sec_gp_reg3;/*! Secure GPIO Register 3 */
uint32_t sec_int_reg0;/*! Secure Interrupt Mask for CPU1 Register 0 */
uint32_t sec_int_reg1;/*! Secure Interrupt Mask for CPU1 Register 1 */
uint32_t sec_gp_reg_lock;/*! Secure GPIO Lock Register */
uint32_t master_sec_reg;/*! Master Secure Level Register */
uint32_t master_sec_anti_pol_reg;
uint32_t cm33_lock_reg; /*! CM33 Lock Control Register */
uint32_t mcm33_lock_reg; /*! MCM33 Lock Control Register */
uint32_t misc_ctrl_dp_reg;/*! Secure Control Duplicate Register */
uint32_t misc_ctrl_reg;
uint32_t misc_tzm_settings;
} tzm_secure_config_t;The product we’re building, a rack-scale computer, is specifically designed to be a centralized, integrated product because that’s what our customers need. This requirement and the design choices we’ve made to meet this need create some daily efficiency challenges for our team. As a remote-first company, we’re designing this product with team members (including the hardware team) across most North American time zones and even multiple continents, so a large portion of our team is not going into the office/lab every day for hands-on access to "production" hardware. At first blush, the design of our product and the design of our team appear to conflict at some level: we value remote work, but we can’t ship entire racks to the homes of our teammates for both practical and economic reasons.
Our racks are rather inconvenient for a home installation: over 2.3 m (7.7') tall, very heavy, and have 3-phase power inputs that aren’t usable in a typical residential setting. Aside from the logistical challenges of a home installation, there’s also the actual cost: these are expensive, and outfitting each remote team member with a full, or even partially populated, rack is economically infeasible. Further, a racked target is not terribly useful for development, as accessing them for debugging is challenging: we have no externally accessible debugging interfaces or other things that can be repurposed as such because our customers don’t want that stuff! We can (and do!) travel some to get hands-on with a full system, but it became clear early on in the development cycle that we needed more convenient ways of being productive remotely.
Remote productivity on this design is a multi-faceted problem and the solution includes robust remote access to fully-built and partially built systems back at HQ, but that alone does not address all the needs.
This post will deal more with the philosophy we have developed around our non-product board designs as we’ve learned what works for us on our journey through remote development. Some of these tools have become pivotal in increasing our remote efficiency, especially early in the design cycle when the "real" systems weren’t very functional and remote accessibility was limited. For more board-by-board specifics, check out a great Oxide and Friends episode where we talked through the genesis of many of these designs. With many of our team members who designed these boards on-hand, it was a great discussion and a lot of fun talking about the role prototypes have played in facilitating our actual product design.
Not a distraction from "real" product design
We fully believe that these small designs, most of which end up taking around a week of engineering time to design, have radically accelerated or augmented our "real" product designs. I detail a couple of specific examples of how this prototype hardware helped us, from enabling software work before any "real" hardware existed, to prototyping circuits like our multiplexed QSPI flash design. Specifically for the QSPI design, the initial circuit just did not work like we expected and using these boards we were able to quickly (and inexpensively!) iterate on the design, directly informing the work on our "real" designs, and in this case, likely saving a spin of our production hardware that wouldn’t have worked. We were even able to connect our SPI mux to extant development hardware from AMD and validate our assumptions before building a server sled. The Oxide and Friends episode mentioned above covers some of these and other stories in more detail.
Our team fully embraces toolmaking up and down the stack: it informs many of our design choices and directions. Bryan recently gave a talk on the concept, and this is yet another application of it. Just like software teams build tools to help build software, we’re building hardware tools to help build hardware and software.
To emphasize how pervasive this culture is in our company, Dan made a great point during the Oxide and Friends chat:
Anyone in the company is empowered to do this.
We don’t need approval or sign-off, we just go do what’s right for Oxide, and I think this quote from Aaron really sums up our team’s viewpoint:
Investments in tools pay off long-term and often faster than you’d think!
We’ve seen time and time again the effort put into these small boards has paid back big dividends in team productivity, development ease, and bug chasing.
Why we needed custom hardware vs off-the-shelf development boards
There are multiple aspects to our need for custom hardware. First, the custom designs supplement our use of off-the-shelf (OTS) hardware. We use many off-the-shelf development boards and even provide support for a number of these boards in Hubris. These are great for many use-cases, but less great when we are trying to model specific circuits or subsystems of our product designs. Second, we have numerous examples of custom boards that were built simply because we could find no useful OTS alternative: boards like the Dimmlet (I2C access to DDR4 SPD EEPROMs) and the K.2 (U.2 → PCIEx4 CEM breakout) fall into this category.

Figure 1. Narrow PMOD-interface board for interfacing with the SPD EEPROMs on the two installed DDR4 DIMMs

Figure 2. PCIe U.2 connector to PCIe x4 CEM connector extender board
Thriftiness in practice
While this strategy of developing prototypes touches on many Oxide values (as discussed below), Thriftiness deserves special attention. Making inexpensive hardware has never been easier! Quick-turn PCB houses, both offshore and onshore, have achieved incredibly low cost while maintaining high quality. We had 50 K.2r2 PCBs with impedance control and a framed stencil fabricated for <$400USD. For something so simple (BOM count <10 parts) we built these in-house using an open-source pick and place machine (Lumen PNP from Opulo), and a modified toaster oven with a Controleo3 controller. We’ve also done hot-plate reflow and hand assembly. And while we will outsource assembly when it makes sense due to complexity or volume, for these simple, low volume designs, we see real benefits in self-building: we can build as few or as many as we want, do immediate bring-up and feed any rework directly into the next batch, and there’s no overhead in working with a supplier to get kitted parts there, quotes, questions etc. A good example of this was on the Dimmlet: I messed up the I2C level translator circuit by missing the chip’s requirements about which side was connected to the higher voltage. Since I was hand-assembling these, I built one, debugged it, and figured out the rework required to make it function. Since this rework included flipping the translator and cutting some traces, catching this issue on the first unit made reworking the remaining ones before going through assembly much easier.
All of that to say, the cost of building small boards is really low. A single prototype run that saves a "real" board re-spin pays for itself immediately. Enabling software development before "real" hardware lands pays for itself immediately. Even when things don’t work out, the cost of failure is low; we lost a few hundred dollars and some engineering time, but learned something in the process.
Because of this low cost, we can use a "looser" design process, with fewer tollgates and a less formal review/approval process. This lowers the engineering overhead required to execute these designs. We can have more informal reviews, a light-weight (if any) specification and allow design iteration to happen naturally. Looking at the designs, we have multiple examples of design refinement like the K.2r2 which improved on the electrical and mechanical aspects of the original K.2, and a refinement to the sled’s bench power connector boards resulting in a more compact and ergonomic design that improves mating with sleds in their production sheet metal.
Experience and the evolution of our strategy
Early in our company’s history, the team built out a development platform,
named the Gemini Bring-up board, representing the core of the embedded
design for our product-- our Gemini complex (Service Processor + Root of Trust
Management Network plane). The resulting platform was a very nice development
tool, with hilarious silkscreen and some awesome ideas that have continued
informing current and future designs, but we rapidly outgrew this first design.
While the major choices held, such as which microcontrollers are present, the
still-nebulous design of the actual product, and subsequent design iteration,
left the periphery of the bring-up board bearing little resemblance to the
final Gemini complex design. The changes came from a variety of unforeseen
sources: the global chip shortage forced BOM changes and a better understanding
of the constraints/needs of our product necessitated architecture changes,
resulting in further drift between this platform and what we intended to
implement in the product.

Figure 3. First custom Oxide hardware with SP and RoT
A re-imagining of what would be most useful gave way to the Gimletlet, a major work-horse for in-house development, designed (and initially hot-plate reflowed) by Cliff. The Gimletlet is essentially a development board using the STM32H7 part that we’re using as our Service Processor (SP) in our product. It provides power and basic board functionality including a couple of LEDs, and a dedicated connector for a network breakout card, and breaks out most of the remaining I/O to PMOD-compatible headers. This choice has been key to enabling a very modular approach to prototyping, recognizing that less is more when it comes to platforms. The Gimletlet design means that we can build purpose-built interface cards without needing to worry about network connectivity or processor support, simplifying the design of the interface cards and able to share a core board support package.

Figure 4. Custom STM32H7 board with I/O breakout to many PMOD interfaces
Our team has learned that modularity is key to making these small proto-boards successful. It does mean workspaces can get a little messy with a bunch of boards connected together, but we’ve found this to be a good balance, allowing our team members to cobble together a small, purpose-built system that meets their specific needs, and allows us to easily share these common, low-cost setups to our distributed team. The modularity also means that storing them is relatively easy as they can be broken down and stashed in small boxes.
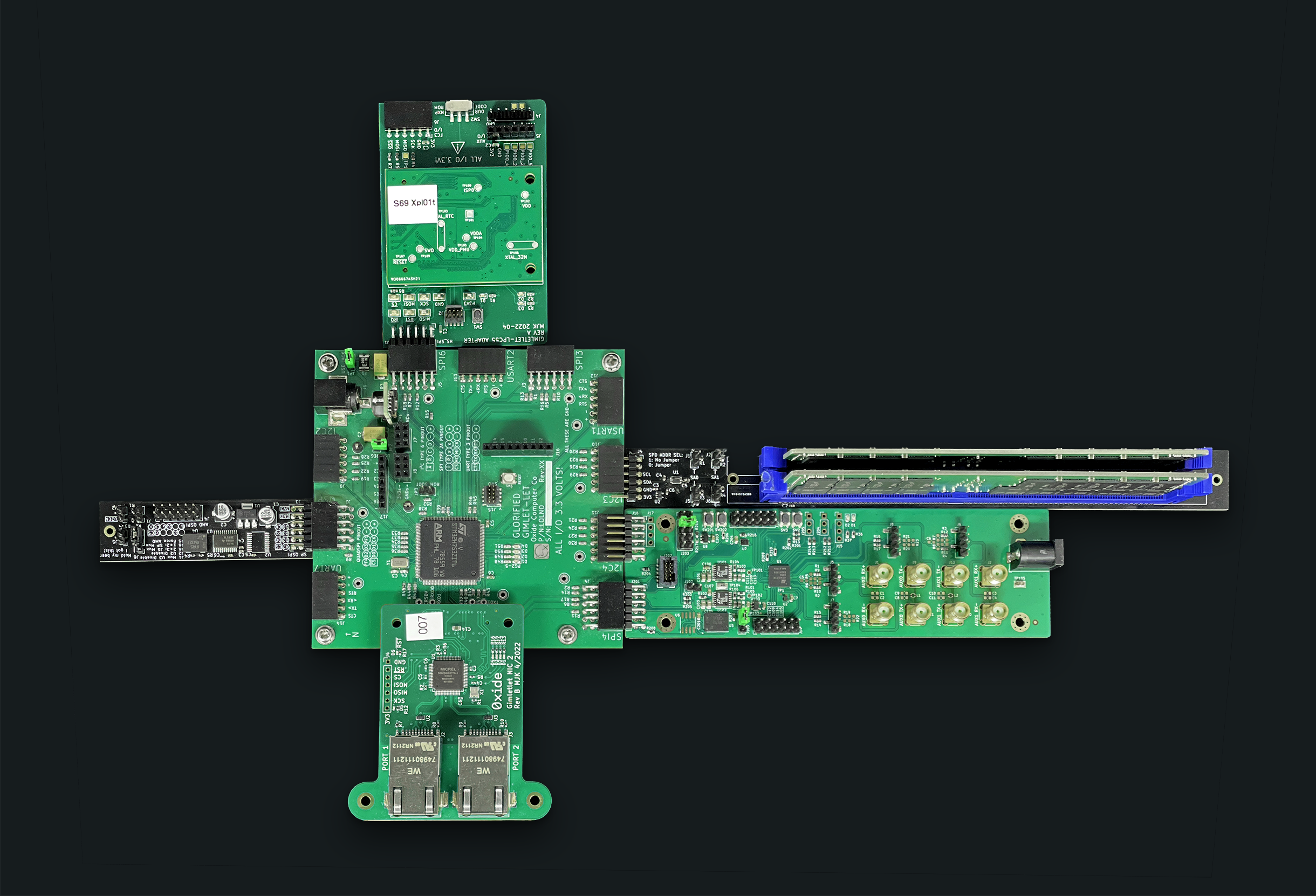
Figure 5. Gimletlet with Igntionlet, SPI MUx, Dimmlet, RoTCarrierCarrier, and RoTCarrier connected
Our values tie-ins
There are some obvious values tie-ins like teamwork and thriftiness as already mentioned, but as I started writing this section I realized we hit more of our values than I had even realized. Rather than attempt to enumerate each one, I wanted to hit on some maybe less-obvious ones:
Humor: The silkscreens on our boards contain jokes, word-play and other silliness because we enjoy making our co-workers laugh and want our work to be fun too. The funny silkscreen is often snuck in post-review, and thus a surprise to co-workers as they open the finished hardware. Engineering demands creativity — I’ve worked at places where silliness baked into a board would be frowned upon, but at Oxide it is supported and even encouraged! This enables team members to bake a little bit of their personality into these designs, while allowing the rest of the team to have fun as it’s discovered.
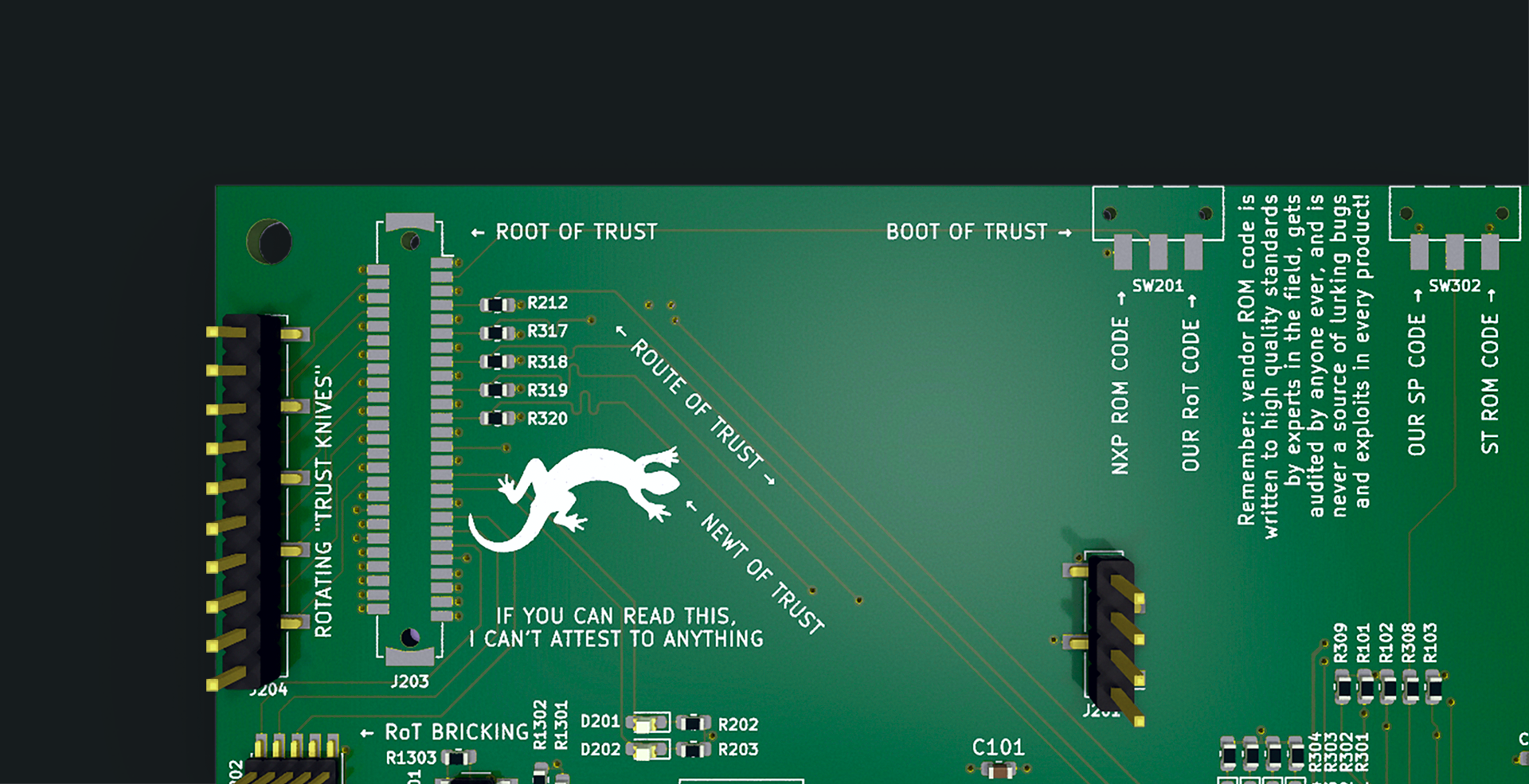
Figure 6. Preview of Gemini Bring up board
Rigor/Urgency: We often find Rigor and Urgency in tension with each other, but in this case, they are complementary. The time from concept to ordering of a PCB on some of these designs is measured in hours or days, not weeks. Being able to move quickly from a paper concept to a physical manifestation of that concept in real hardware has been instrumental in grounding our assumptions and informing our designs. We’re able to quickly iterate in areas where we have questions, driving resolution without holding up the rest of the design. This work directly contributes to better architecture and circuit design decisions in our "real" designs.
Transparency/Responsibility/Teamwork: We believe in openness, including our own designs, so we’re opening up the various proto-board design repositories for reference and hope that something there is useful in your own hardware endeavors. These designs are things that we wished existed and so created them, some of these may be a bit specific for our use-cases, but there are some generally useful things there too. These are mostly KiCAD designs and support for them is "as-is" since we’re focused on getting our product out the door, but feel free to reach out in the repo with questions and we’ll attempt to answer on a best-effort basis.